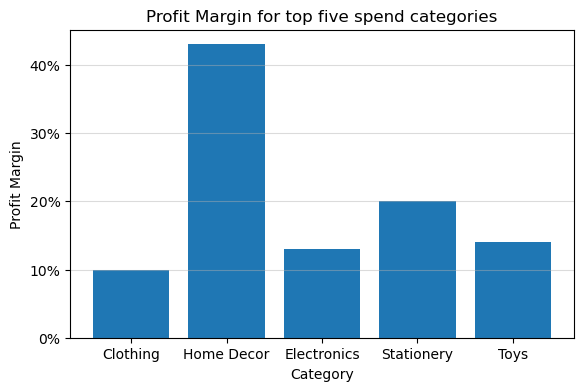
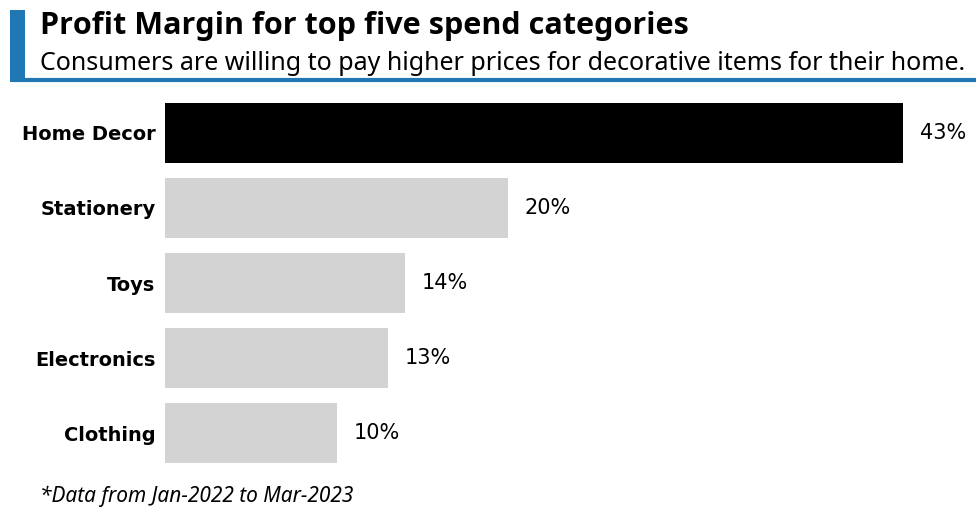
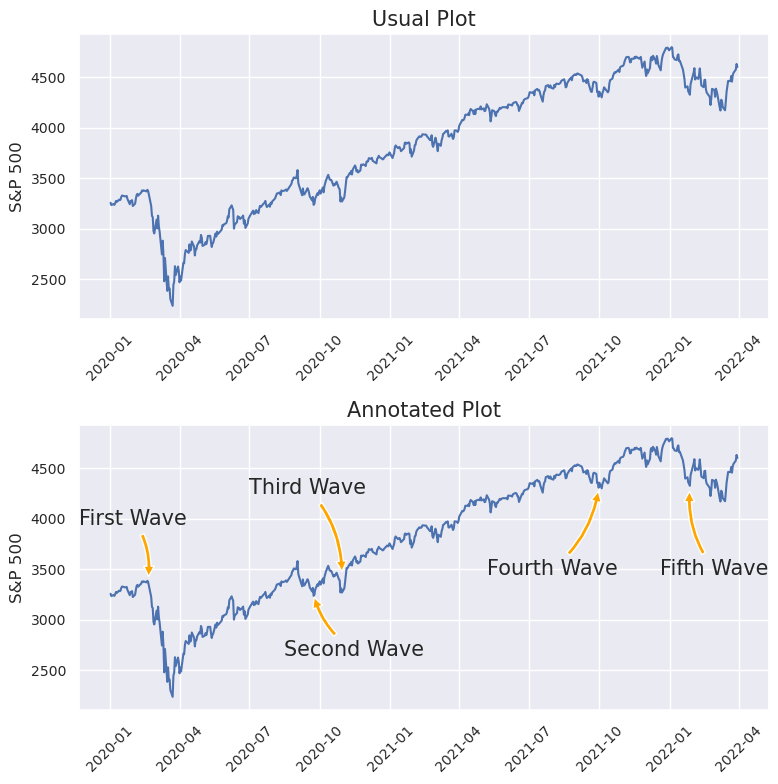
import warnings
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.impute import KNNImputer, SimpleImputer
# 경고 메시지 무시
warnings.filterwarnings("ignore")
sns.set()
# 플롯을 위한 기본 설정
plt.rcParams["font.family"] = ["Noto Sans", "sans-serif"]
colors = [
"#fe7c73",
"#2471A3",
"#3498DB",
"#27AE60",
"#82E0AA",
"#D35400",
"#5D6D7E",
"#E74C3C",
"#21618C",
"#B7950B",
"#46C7C7",
"#00B9FF",
"#FF7051",
"orange",
"darkorange",
"tomato",
"coral",
"limegreen",
"lightsalmon",
]
# --- 1. 결측치가 포함된 더미 데이터셋 생성 ---
size = 1000
data = np.random.normal(loc=2, scale=2, size=(size, 3)) # 정규분포를 따르는 무작위 데이터 생성
mask = np.random.rand(size, 3) < 0.2 # 20% 확률로 결측치를 만들기 위한 마스크(mask) 생성
data[mask] = np.nan # 마스크를 적용하여 결측치(NaN) 설정
# --- 2. 다양한 방법으로 결측치 대체 ---
# 평균값 대체(Mean Imputation)
mean_imputer = SimpleImputer(strategy="mean")
data_imputed_mean = mean_imputer.fit_transform(data)
# 0으로 대체(Zero Imputation)
zero_imputer = SimpleImputer(strategy="constant", fill_value=0)
data_imputed_zero = zero_imputer.fit_transform(data)
# kNN 대체 (n_neighbors=5)
knn_imputer = KNNImputer(n_neighbors=5)
data_imputed_knn = knn_imputer.fit_transform(data)
# --- 3. Subplot을 사용하여 4개의 플롯을 하나로 합치기 ---
# 2x2 서브플롯 그리드(grid) 생성. figsize로 전체 크기 조절
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(8, 6))
# (0, 0) 위치: 원본 데이터 분포
axes[0, 0].hist(data.flatten(), bins=45, edgecolor="black", color=colors[1])
axes[0, 0].set_title("Original Distribution", size=14, pad=10)
axes[0, 0].set_xlabel(
"Value",
size=12,
)
axes[0, 0].set_ylabel(
"Frequency",
size=12,
)
# (0, 1) 위치: 평균값 대체(Mean Imputation) 분포
axes[0, 1].hist(data_imputed_mean.flatten(), bins=45, edgecolor="black", color=colors[16])
axes[0, 1].set_title("Mean Imputation", size=14, pad=10)
axes[0, 1].set_xlabel(
"Value",
size=12,
)
axes[0, 1].set_ylabel(
"Frequency",
size=12,
)
# (1, 0) 위치: 0으로 대체(Zero Imputation) 분포
axes[1, 0].hist(data_imputed_zero.flatten(), bins=45, edgecolor="black", color=colors[16])
axes[1, 0].set_title("Zero Imputation", size=14, pad=10)
axes[1, 0].set_xlabel(
"Value",
size=12,
)
axes[1, 0].set_ylabel(
"Frequency",
size=12,
)
# (1, 1) 위치: kNN 대체(kNN Imputation) 분포
axes[1, 1].hist(data_imputed_knn.flatten(), bins=50, edgecolor="black", color=colors[18])
axes[1, 1].set_title("kNN Imputation (k=5)", size=14, pad=10)
axes[1, 1].set_xlabel(
"Value",
size=12,
)
axes[1, 1].set_ylabel(
"Frequency",
size=12,
)
# 레이아웃 자동 조정 (메인 제목과 겹치지 않도록 rect 파라미터로 상단 여백 확보)
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
# 모든 플롯을 한 번에 표시
plt.show()